Ethereum RLP: Explication
Avant de continuer la lecture, je tiens à dire que cet article est une tentative d’explication du schéma d’encodage RLP, utilisé par Ethereum, d’une manière simple et concrète avec des exemples.
Ce qui va suivre, c’est une tentative d’explication de ce que j’ai pu comprendre de l’encodage RLP qu’Ethereum utilise. Et c’est à vous de chercher encore et de valider ou non ce que vous aller rencontrer tout le long de cet article.
Définition:
Le schéma d’encodage RLP (Recursive Length Prefix) est un schéma de sérialisation d’objets spatialement efficace utilisé dans Ethereum.
La spécifité de ce type d’encodage est expliqué dans la page jaune (yellow paper) et dans le wiki d’Ethereum [source: Documentation de web3js]
Plus concrètement, RLP est le format de sérialisation utilisé par Ethereum pour sérialiser les objets en octets. Il encode uniquement la structure des données qu’il code, il ne sait rien du type d’objet qu’il était avant de le coder. Cela réduit la taille globale de l’encodage mais nécessite que le décodeur des octets sache quel type d’objet il recherche.
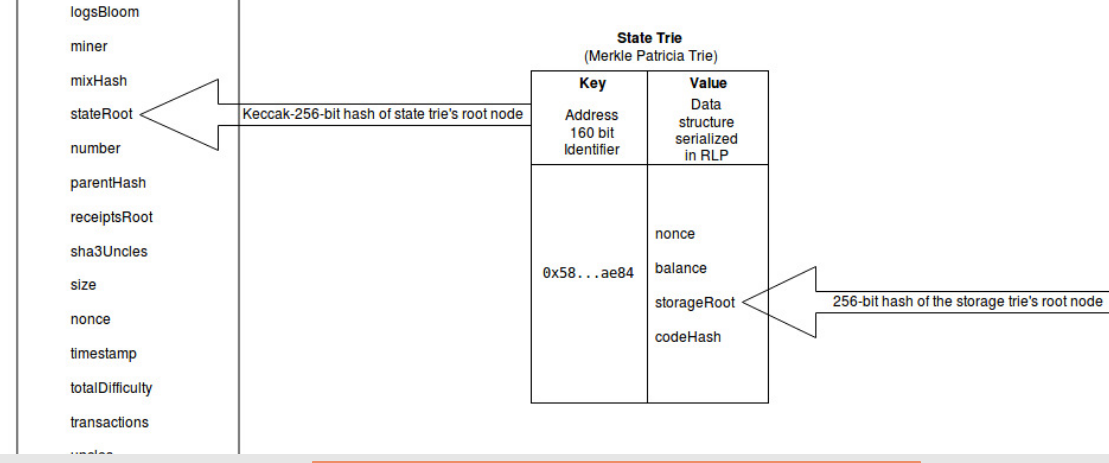
Mais, à quoi sert RLP ?
RLP est le plus souvent utilisé dans Ethereum lors de l’envoi de données et lors de la sauvegarde de l’état dans le schéma d’authentification cryptographique Patricia Tree utilisé par Ethereum.
Les règles du schéma d’encodage RLP:

La fonction d’encodage RLP comme expliquée dans la documentation d’Ethereum prend un élément, et ce dernier est défini comme suit:
- Une chaîne de caractères (String) va être convertie en liste d’octets (byte array)
- Une liste d’éléments est un élément
Exemples:
Tous ces objets sont des éléments valides pour un encodage RLP:
"cat"[]["cat"][["cat"], "hello", [], ""]
En total, il y a quatre différentes règles fondamentales lors de l’encodage RLP qui sont:
- Pour un seul octet (byte) dont la valeur est dans la plage
[0x00, 0x7f], le retour de l’encodage RLP de cet octet est lui même. Sinon, si une chaîne a une longueur de 0 à 55 octets, le retour de l’encodage RLP consiste en un seul octet de valeur0x80plus la longueur de la chaîne suivie de la chaîne. La plage du premier octet est donc[0x80, 0xb7]. - Si une chaîne a une longueur de plus de 55 octets, le retour de l’encodage RLP consiste en un seul octet de valeur
0xb7plus la longueur en octets de la longueur de la chaîne sous forme binaire, suivie de la longueur de la chaîne, suivie de la chaîne. Par exemple, une chaîne de longueur 1024 serait codée sous la forme"\xb9\x04\x00"suivie de la chaîne. La plage du premier octet est donc[0xb8, 0xbf]. - Si la charge utile totale d’une liste (c’est-à-dire la longueur combinée de tous ses éléments codés en RLP) est comprise entre 0 et 55 octets, le codage RLP consiste en un seul octet de valeur
0xc0plus la longueur de la liste suivie de la concaténation du retour de l’encodages RLP des éléments. La plage du premier octet est donc[0xc0, 0xf7]. - Si la charge utile totale d’une liste est supérieure à 55 octets, le codage RLP consiste en un seul octet de valeur
0xf7plus la longueur en octets de la longueur de la charge utile sous forme binaire, suivie de la longueur de la charge utile, suivie par la concaténation du retour de l’encodages RLP des éléments. La plage du premier octet est donc[0xf8, 0xff].
Script d’encodage RLP écrit en Python
# Source: https://github.com/ethereum/wiki/wiki/RLP
def rlp_encode(input):
if isinstance(input,str):
if len(input) == 1 and ord(input) < 0x80: return input
else: return encode_length(len(input), 0x80) + input
elif isinstance(input,list):
output = ''
for item in input: output += rlp_encode(item)
return encode_length(len(output), 0xc0) + output
def encode_length(L,offset):
if L < 56:
return chr(L + offset)
elif L < 256**8:
BL = to_binary(L)
return chr(len(BL) + offset + 55) + BL
else:
raise Exception("input too long")
def to_binary(x):
if x == 0:
return ''
else:
return to_binary(int(x / 256)) + chr(x % 256)
Exemples d’encodage RLP:
- Chaîne vide
""= RLP =>['0x80']: La chaîne vide a une longueur égale à zéro. Du coup, pour encoder une chaîne vide on va passer à la deuxième partie de la première règle, c’est à dire: La longueur de la chaîne est comprise entre 0 et 55 octets, du coup on ajoute0x80 + longueur d'une chaîne vide = 0x80 - Liste vide
[]= RLP =>['0xc0']: La liste vide a une longueur égale à zéro. Donc, on s’intéresser à cette partie du code:elif isinstance(input,list): output = '' for item in input: output += rlp_encode(item) return encode_length(len(output), 0xc0) + output- Avec:
output = '' - Et
encode_length(len(output), 0xc0) + output - Qui va être égale à
encode_length(0, 0xc0) + '' - Qui est:
chr(0 + 0xc0) - Donc:
hex(ord(chr(0 + 0xc0)))est égale àhex(190)='0xc0'
- Avec:
- La chaîne de caractère
"dog"= RLP =>[0x83, 'd', 'o', 'g']:"dog"est une chaîne de caractères de longueur égale à 3 (len([ord(k) for k in "dog"])est égale à 3). Donc on ajoute un offsethex(0x80 + 3)qui est égale à0x83plus la chaîne elle même qui est :$> [hex(0x80 + 3)] + list("dog") ['0x83', 'd', 'o', 'g'] # Ou en hexadécimal : $> [hex(0x80 + 3)] + list(hex(ord(k)) for k in "dog") `['0x83', '0x64', '0x6f', '0x67'] - La liste
["cat", "dog"]= RLP =>[0xc8, 0x83, 'c', 'a', 't', 0x83, 'd', 'o', 'g']:
# L'encodage RLP peut être traduit comme suit:
$> from itertools import chain
$> fst_encode = list(chain.from_iterable([[hex(0x80 + len(k))] + list(k) for k in ["cat", "dog"]]))
$> fst_encode
['0x83', 'c', 'a', 't', '0x83', 'd', 'o', 'g']
# On a 8 éléments dans le premier encodage compris entre 0 et 55
# Donc on ajoute un offset égal à 0xc0 + longueur du premier encodage
$> [hex(0xc0 + len(fst_encode))] + fst_encode
# Et on aura l'encodage RLP:
['0xc8', '0x83', 'c', 'a', 't', '0x83', 'd', 'o', 'g']
## Pour la format en hexadécimale
$> to_rlp = ["cat", "dog"]
$> fst_encode_hex = list(chain.from_iterable([[hex(0x80 + len(k))] + [hex(ord(j)) for j in k] for k in to_rlp]))
$> fst_encode_hex
['0x83', '0x63', '0x61', '0x74', '0x83', '0x64', '0x6f', '0x67']
$> [hex(0xc0 + len(fst_encode))] + fst_encode_hex
['0xc8', '0x83', '0x63', '0x61', '0x74', '0x83', '0x64', '0x6f', '0x67']
- L’entier
15= RLP =>[0x0f]:# En effet, l'encodage en caractère de l'entier 15 est $> chr(15) '\x0f' # Ou d'une autre manière # (15).to_bytes(1, byteorder='big') # b'\x0f' $> hex(15) '0xf' # Et 15 est un seul octet compris entre 0x00 et 0x7f $> 0x00 <= 15 <= 0x7f True # Donc, le retour de l'encodage RLP est: ['\x0f`] - L’enter
1024= RLP =>[0x82, 0x04, 0x00]:
# L'encodage RLP de 1024 peut être traduit comme suit:
# PS:
# Ethereum support la notation de Big endian
# https://docs.python.org/3/library/stdtypes.html#int.to_bytes
# Et On supprime les leading zeros
## Le format encodé de 1024 en bytes est:
$> to_encode = (1024).to_bytes(2, byteorder='big')
$> to_encode
b'\x04\x00'
# Ou bien d'une autre manière
# import struct
# struct.pack('>I', 1024).decode('ascii').lstrip('\x00').encode()
## Au final, l'encodage RLP sera:
# On ajoute un offset de 0x80 parce que la longueur du byte array de 1024
# est compris entre 0 et 0x7f
$> [hex(0x80 + len(to_encode))] + list(hex(k) for k in to_encode)
['0x82', '0x4', '0x0']
- La liste
[ [], [[]], [ [], [[]] ] ]= RLP =>['0xc7', '0xc0', '0xc1', '0xc0', '0xc3', '0xc0', '0xc1', '0xc0']:
# Pour ce type complexe, on va essayer de le découper
# en opérations simples
[ [ ], [ [ ] ], [ [ ], [[]] ] ]
^ ^^^^^^ ^^^^^^^^^^^^^
[ '0xc0', '0xc1', '0xc0' , '0xc3', '0xc0', '0xc1', '0xc0' ]
^^^^ ^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
liste vide liste avec 1 elm liste avec 3 elms
# On 7 éléments, donc on ajoute l'offset:
# 0xc0 + 7 vu que la longueur est comprise entre 0 et 55 octets:
# Et on obtien:
['0xc7', '0xc0', '0xc1', '0xc0', '0xc3', '0xc0', '0xc1', '0xc0' ]
- **La chaîne
"Lorem ipsum dolor sit amet, consectetur adipisicing elit"= RLP =>['0xb8', '0x38', '0x4c', '0x6f', ..., '0x6c', '0x69', '0x74']:
# La longueur de la chaîne est:
$> a = 'Lorem ipsum dolor sit amet, consectetur adipisicing elit'
$> len(a)
56
# Donc, on est dans le cas où la longueur de la chaîne de caractère est supérieure à 55
# Donc, on ajoute un offset:
$> offset = [hex(0xb7 + 1), hex(len(a))]
# Et l'encodage RLP final est:
$> offset + list(a)
['0xb8', '0x38', 'L', 'o', 'r', ..., 'l', 'i', 't']
- Un dernier exemple, les booléens sont encodés en RLP comme suit:
true= RLP =>0x01: est évaluée comme l’entier1représenté en0x01$> (1).to_bytes(1, byteorder='big') b'\x01'false= RLP =>0x80: est évaluée comme la valeurnull(chaîne vide)
Donc, au final, selon la documentation d’ethereum le premier octet (byte) des données encodées représente le type de l’objet encodé en RLP, c’est à dire si le premier byte est dans la rangée:
[0x00, 0x7f]: C’est un byte[0x80, 0xbf]: C’est une chaîne de caractère[0xc0, 0xff]: C’est une liste
Et c’est ainsi, qu’on peut décoder les données en RLP. Vous pouvez suivre les étapes de décodage sur ce lien et peut être je ferai un autre article expliquant comment faire pour décoder des données en RLP.
Mais pourquoi compliquer la vie en encodant les données ?
La réponse peut être simple, mais essayez de méditer dessus:
Efficacité, plus d'espace de stockage, anonymat et parce qu'on peut le faire :D

Commentaires